 CloudRadial
CloudRadial
Understanding RPS Scores: How to Know When Your MSP Is Actually Ready for AI Deployment
Picture this: you send out CSAT surveys after tickets close, and maybe you track NPS quarterly. You get back responses from 15-20% of your clients....



Enterprise-grade infrastructure with the flexibility MSPs demand
Perfectly tailored AI that knows your specific MSP

Build your own Shopify-like store with your PSA products & distributors
Have clients to submit tickets directly to your PSA, freeing up your team's time
Pre-triage and route tickets correctly with the help of AI

Deliver instant, accurate answers that can help achieve zero-touch resolution
Picture this: you send out CSAT surveys after tickets close, and maybe you track NPS quarterly. You get back responses from 15-20% of your clients. The scores look decent. You feel pretty good about your service delivery.
Then you deploy AI, and it's a disaster. Clients complain. Your team loses confidence. You pull it back and wonder what went wrong.
Here's what went wrong: you deployed AI based on incomplete data from a tiny sample of interactions, and you had no idea whether your service delivery was actually consistent enough for AI to learn from.
CSAT and NPS surveys only capture feedback from clients motivated enough to respond—usually the very happy or very unhappy ones. You're flying blind on 80% of your service delivery, making critical AI deployment decisions based on a biased sample.
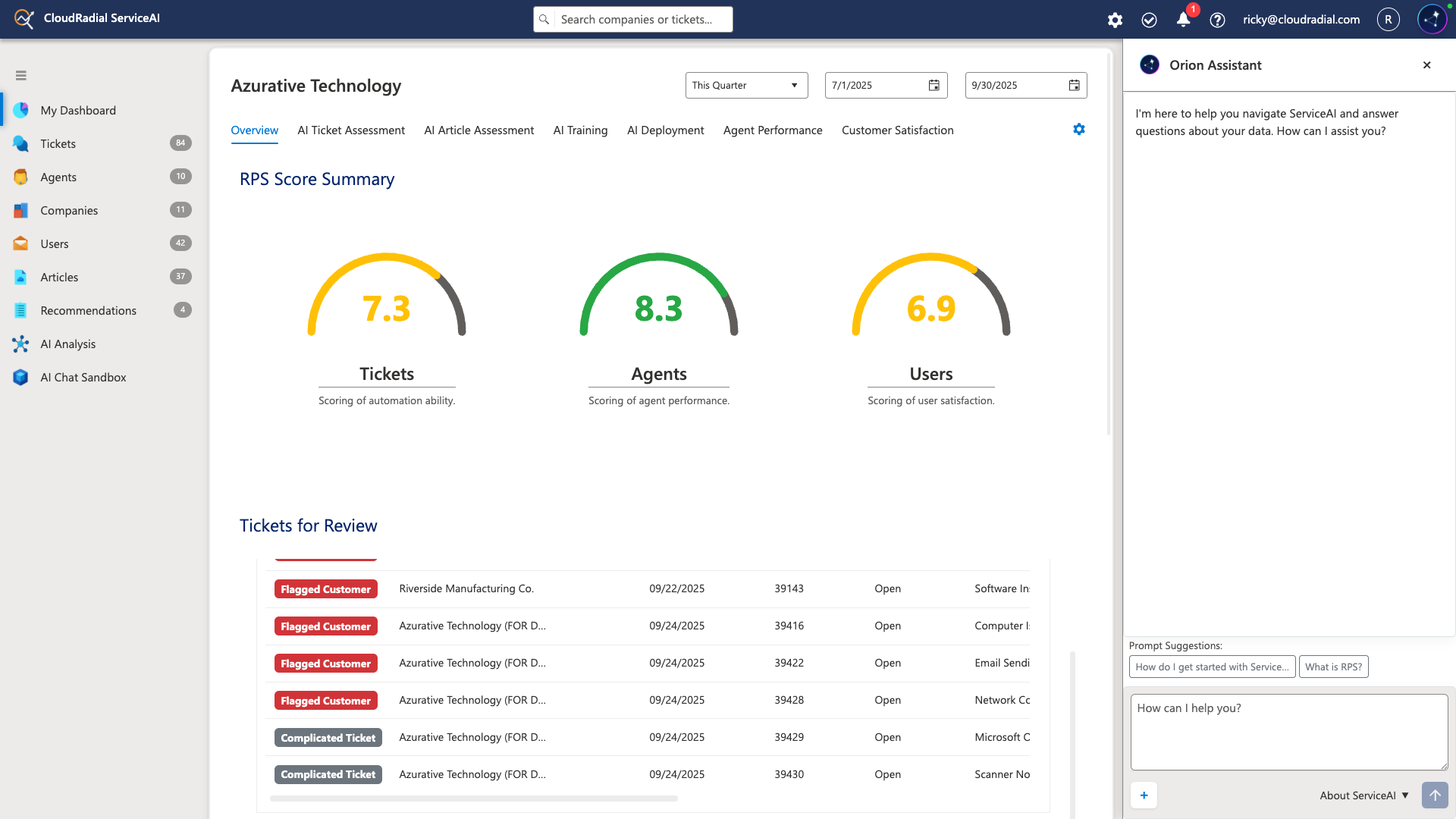
Relative Performance Scores (RPS) change everything by analyzing 100% of your service delivery automatically.
Not surveys. Not samples. Every ticket. Every interaction. Every technician response.
RPS gives you three critical metrics that determine whether your AI organism is ready for deployment. And more importantly, tells you exactly what to fix if you're not ready.
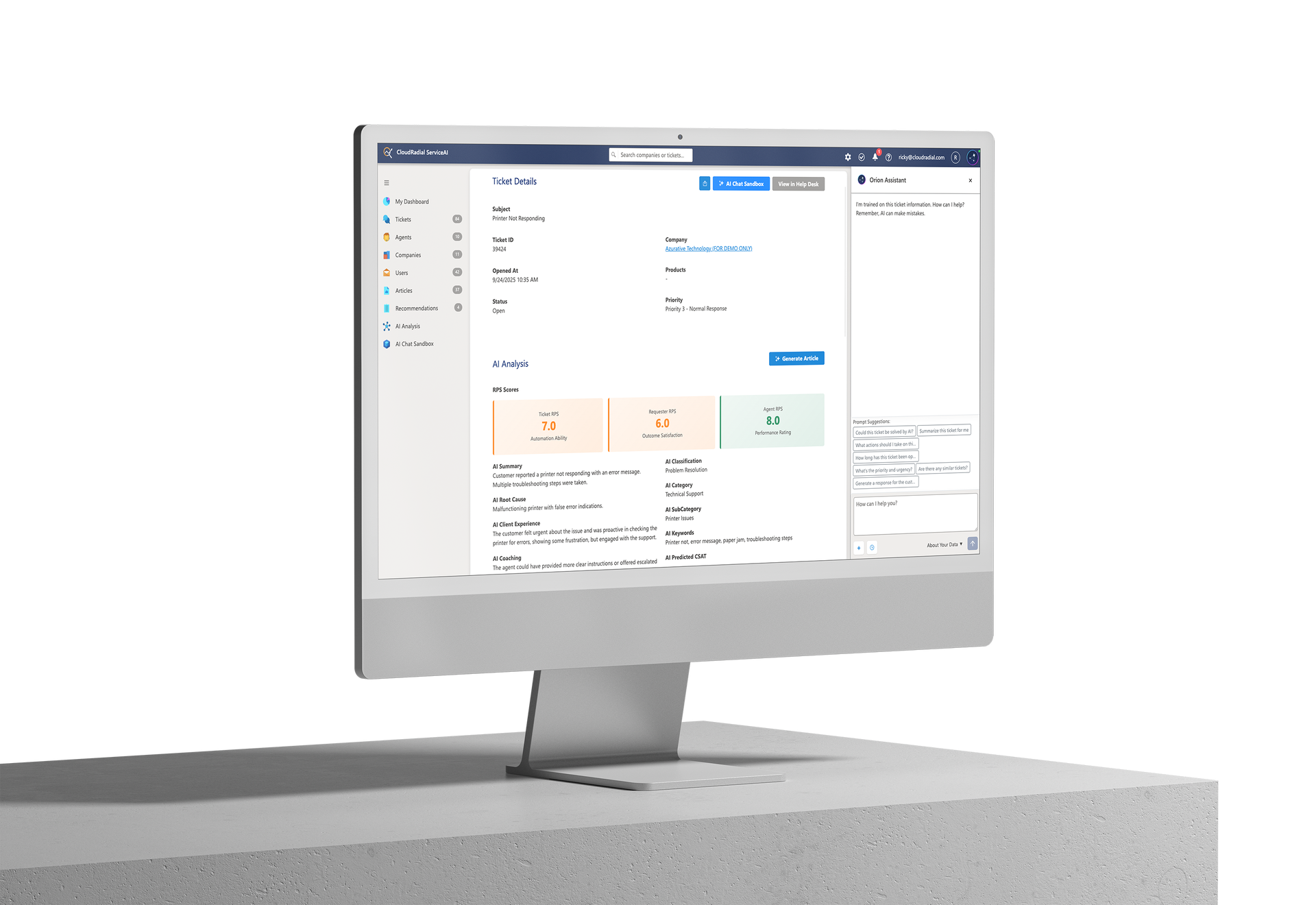
Ticket RPS measures how confident ServiceAI is that it can successfully resolve your tickets without human intervention.
It analyzes the quality of your public-facing ticket notes—the responses your clients actually see. It evaluates clarity, completeness, consistency, and whether responses follow logical troubleshooting processes.
Here's what the scores mean:
Your ticket responses are inconsistent, unclear, or incomplete. Maybe your techs write great internal notes but forget to update clients with public-facing information. Maybe responses vary wildly depending on who answers the ticket. Either way, if ServiceAI can't learn consistent patterns from your ticket history, it can't reliably help clients.
Don't deploy AI here. You'll create client frustration and team confusion.
You're close, but not quite ready. Some tickets show excellent documentation. Others have gaps. You need to standardize your processes and improve documentation consistency before AI deployment.
The good news? ServiceAI identifies exactly which ticket types need work, and which are ready for AI assistance. You can start deploying AI for high-scoring ticket categories while improving others.
Your ticket documentation is clear, consistent, and complete. ServiceAI has learned strong patterns from your historical data and can confidently assist with these ticket types.
You're ready to test zero-touch resolution, letting AI handle these tickets without tech review for final responses.
This scoring system removes guesswork. You know exactly where you stand and what needs improvement before deployment.
Agent RPS evaluates individual technician performance and consistency.
Let's be clear about what this isn't: it's not about catching people doing things wrong. It's not about punishment or micromanagement.
It's about identifying who should be coached versus who should train others and the AI.
Agent RPS analyzes standardized factors including:
Here's why this matters for AI deployment:
Your highest-scoring technicians should train ServiceAI. Their responses represent your best practices. Their troubleshooting approaches should be the model AI learns from. When you're building knowledge base articles or refining AI behavior rules, these are the people who should guide the process.
Your mid-scoring technicians need targeted coaching. Maybe they're great at technical troubleshooting but weak on client communication. Maybe they're responsive but inconsistent in following processes. Agent RPS identifies specific improvement areas for each person.
Your lower-scoring technicians need structured development. They're not bad techs. They might be new or they might have gaps in specific areas. But letting AI learn from inconsistent performance will create inconsistent AI responses.
The beautiful part? Agent performance reports track improvement over time. You can see when coaching is working. You can measure the impact of training. You can watch junior techs develop into senior-level performers and then let them start training the AI.
User RPS assesses client satisfaction and interaction patterns.
Not every client is ready for AI interactions at the same time. Some clients love self-service and will embrace ChatAI immediately. Others need more handholding and should wait until your AI is proven and refined.
User RPS helps you identify:
High-scoring clients (8+): These are your AI early adopters. They communicate clearly. They respond positively to technician interactions. They're likely to appreciate 24/7 AI assistance and instant resolution for routine issues. Deploy ChatAI to these clients first; they'll give you valuable feedback and help refine the system.
Mid-scoring clients (6-7.9): These clients are generally satisfied but may have occasional frustrations or communication challenges. Deploy AI to them in your second wave, after you've refined responses based on high-scoring client feedback.
Lower-scoring clients (below 6): These clients may be difficult communicators, frequently frustrated, or struggling with consistent issues in their environment. Don't deploy ChatAI to them early—wait until your AI is proven and polished. Protect both the client relationship and your team's confidence in the system by being strategic about rollout.
User RPS also helps you customize AI behavior for different client types. Maybe Client A prefers technical details while Client B needs simplified explanations. Maybe some clients want proactive alerts while others prefer reactive support. RPS scoring gives you the data to make these customization decisions intelligently.
Traditional metrics tell you what happened in the past with a small sample. RPS tells you what will happen in the future with complete data.
Traditional metrics are lagging indicators. RPS is a predictive indicator.
When you deploy AI based on CSAT scores, you're guessing. When you deploy based on RPS scores, you know.
Here's what that looks like in practice:
Your CSAT scores are 4.5 out of 5. You feel great. You deploy ChatAI across all clients.
Within two weeks, you're getting complaints. AI responses don't match what your team would say. Some ticket types get handled well, others poorly. You can't figure out why.
RPS would have shown you that while some ticket types scored 8+, others scored 5 or below. Your aggregate CSAT looked good because clients were rating overall satisfaction, not differentiating between ticket types. You deployed AI before you were ready.
Your CSAT scores are 4.2 out of 5. Pretty good, but not amazing.
But RPS shows you that password resets, email issues, and basic software questions all score 9+. Your techs handle these consistently and thoroughly. Meanwhile, complex network troubleshooting scores 6—there's too much variation in approach.
So, you deploy ChatAI for the high-scoring ticket types only. Clients love the instant response for routine issues. Your techs love being freed from repetitive questions. Complex issues still go to humans.
You use the time savings to standardize network troubleshooting processes, raising that RPS score from 6 to 8 over three months. Then you expand AI to cover those ticket types too.
Same overall CSAT, completely different AI deployment strategy, dramatically better results.
Here's what makes RPS truly powerful: it creates a continuous improvement cycle.
This is the learning compound effect in action. Your service delivery gets better. Your AI gets smarter. Your competitive advantage grows.
AI deployment shouldn't be a leap of faith. It should be a data-driven decision based on objective readiness indicators.
RPS scores give you that objectivity. They tell you when you're ready, what needs improvement, and which clients to deploy to first.
They turn "I hope this works" into "I know this will work."
The MSPs implementing AI successfully aren't lucky. They're strategic. They're measuring the right things. They're deploying based on data, not hope.
Get a free AI readiness assessment that shows you how to analyze your ticket history and shows you exactly where you stand. No more guesswork.

Picture this: you send out CSAT surveys after tickets close, and maybe you track NPS quarterly. You get back responses from 15-20% of your clients....

You've seen the headlines. AI has the power to transform IT service delivery.
Based on a conversation between Ricky Cecchini (VP of Product, CloudRadial) and Mike Parfitt (CEO, Team Metalogic) on ServiceAI, CloudRadial's...